用 Python 实现自动批量打分评论指定 CSDN 账号内所有下载过待评论的资源。
GitHub 仓库地址:https://github.com/mzlogin/csdncommenter
可通过 pip 安装运行:
pip install csdncommenter
csdncommenter
背景
CSDN 账号过一段时间就会累积几十个下载过但是未评论打分的资源,虽然现在上传了一些资源供别人下载后基本不愁积分,但是为了可持续发展,还是把评论一下就能顺手拿了的这种积分不客气地收入囊中吧!不过手动一个一个去评论真的很蛋疼……特别是 CSDN 还设了两个评论间隔不能小于 60 秒、刚刚下载的资源十分钟内不能评论的限制,评论几十个就得至少花个几十分钟折腾,所以想想这种耗时、无脑的活还是交给程序来完成吧。
对于这类模拟 HTTP 请求然后可能频繁用到页面解析和正则表达式之类的活,用 C++ 写还是有点蛋疼的,用我那半生不熟的 Python 练练手正合适。
遂在 GitHub 上建了个仓库开工,地址在这里:https://github.com/mzlogin/csdncommenter。
Update 2016/08/10:当前 CSDN 貌似已经取消了评论返积分的规则,我看了下我的得分记录,最近一次评论得分是在 2015/11/15。
分析
使用 Fiddler 把登录 - 到待评论页面 - 评论的完整流程抓了一下,整理程序逻辑大致如下:
注:如下 HTTP 请求均使用同一个 SESSION。
手动输入 CSDN 的用户名和密码。
用
GET方法从 https://passport.csdn.net/account/login 页面获取lt、execution和_eventId等参数。将第 1 步中的用户名和密码,还有第 2 步中得到的参数
POST给 https://passport.csdn.net/account/login ,从 Response 中判断是否登录成功——我采用的依据是 status_code 为 200 且 Reponse 内容中有lastLoginIP。用
GET方法从 http://download.csdn.net/my/downloads 页面获取已下载资源总页数。从最后一个pageliststy的href中得到。根据第 4 步中得到的总页数,根据每个页面 num 拼得 url 为 http://download.csdn.net/my/downloads/num ,使用
GET方法访问之拿到该页面中所有待评论资源 ID。从所有class="btn-comment"的a标签的href中得到。在进行第 5 步的过程中,如果 num 为 1 的页面里有
<span class="btn-comment">存在,那说明存在 10 分钟以内下载,暂时不能评论的资源,这时循环检查最多 11 次,每次检查完如果发现还需要等待就过一分钟再检查,进到不再需要等待或者超过 11 次为止。对第 5 步中得到的所有待评论资源 ID 依次进行间隔至少 60S 的打分评论,根据资源的现有评星打分,不对资源评分造成不良影响。根据打出的 1 到 5 星,对应一句英文短句评论。出乎我意料的是评论这一步竟然也是用
GET就可以做,http://download.csdn.net/index.php/comment/post_comment 后面带上sourceid、content(评论内容)、rating(打分)和t(时间戳)参数就可以。评论成功会返回({"succ":1}),失败会返回「两次评论需要间隔 60 秒」、「您已经发表过评论」等之类的msg。获取资源的现有评星的方法是从 http://download.csdn.net/detail/<资源所有者 ID>/<资源 ID> 页面获取
<span style="width:75px" class="star-yellow"></span>这一段内容,其中的75px表示为五星,如果是0px表示为零星,即每加一星增加 15px。
最终运行截图如下:
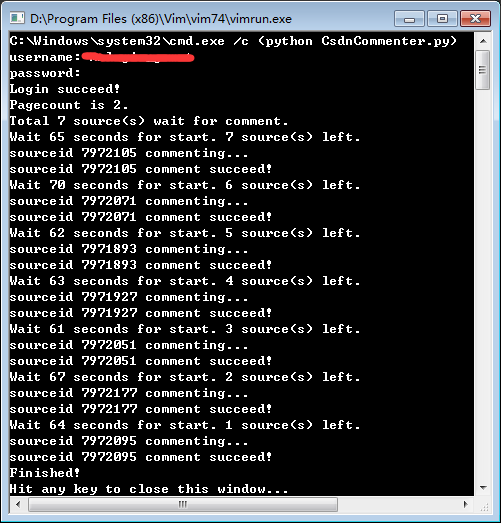
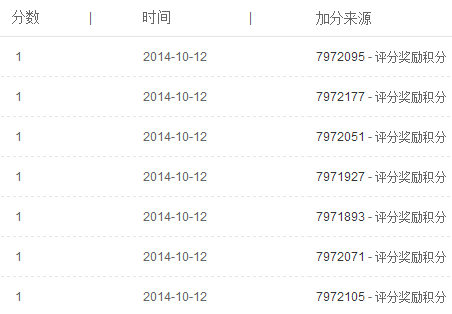
确认这种方式能有效拿到 CSDN 的分数:
总结
- 用 Python 干这种类型的活还是很有优势的,requests 和 BeautifulSoup 简直神器啊!
- 我那点蹩脚的 Python 底子之所以能还比较顺利地把这个流程写下来,实际上也得亏 CSDN 对请求的验证相对较松,比如像我代码里那样写,
User-Agent是带有Python字样的,而且很显然不是浏览器在访问,但 CSDN 并未对此作限制。
源码
没有找到从 Github Pages 引用 Github 仓库里的源码的方法,所以把 py 文件放到一个 gist 里了,引用如下:
(Gist 前几天被伟大的墙封了,还是直接贴上代码吧。2014/11/5 update)
(GitHub 仓库:mzlogin/csdncommenter,现在可以通过 pip 安装使用了 pip install csdncommenter 然后 csdncommenter。2015/10/27 update)
# File : csdncommenter.py
# Author : Zhuang Ma
# E-mail : chumpma(at)gmail.com
# Website: https://mazhuang.org
# Date : 2016-07-26
import requests
from BeautifulSoup import BeautifulSoup
import getpass
import time
import random
import re
import urllib
import traceback
class CsdnCommenter():
"""Csdn operator"""
def __init__(self):
self.sess = requests.Session()
def login(self):
"""login and keep session"""
username = raw_input('username: ')
password = getpass.getpass('password: ')
url = 'https://passport.csdn.net/account/login'
html = self.getUrlContent(self.sess, url)
if html is None:
return False
soup = BeautifulSoup(html)
lt = self.getElementValue(soup, 'name', 'lt')
execution = self.getElementValue(soup, 'name', 'execution')
_eventId = self.getElementValue(soup, 'name', '_eventId')
data = {
'username' : username,
'password' : password,
'lt' : lt,
'execution' : execution,
'_eventId' : _eventId
}
response = None
try:
response = self.sess.post(url, data)
except:
# traceback.print_exc()
pass
return self.isLoginSuccess(response)
def autoComment(self):
"""main handler"""
if self.getSourceItems() is False:
print('No source can comment!')
return
print('Total %d source(s) wait for comment.' % len(self.sourceitems))
nhandled = 0
for sourceid in self.sourceitems.keys():
left = len(self.sourceitems) - nhandled
sec = random.randrange(61,71)
print('Wait %d seconds for start. %s source(s) left.' % (sec, left))
time.sleep(sec)
self.comment(sourceid)
nhandled += 1
print('Finished!')
def getSourceItems(self):
"""get (sourceid,username) couples wait for comment"""
self.sourceitems = dict()
pagecount = self.getPageCount()
if pagecount == 0:
return False
print('Pagecount is %d.' % pagecount)
pattern = re.compile(r'/detail/([^/]+)/(\d+)#comment')
for n in range(1, pagecount + 1):
if n == 1:
self.waitUncommentableSourceIfNecessary()
url = 'http://download.csdn.net/my/downloads/%d' % n
html = self.getUrlContent(self.sess, url)
if html is None:
continue
soup = BeautifulSoup(html)
sourcelist = soup.findAll('a', attrs={'class' : 'btn-comment'})
if sourcelist is None or len(sourcelist) == 0:
continue
for source in sourcelist:
href = source.get('href', None)
if href is not None:
rematch = pattern.match(href)
if rematch is not None:
self.sourceitems[rematch.group(2)] = rematch.group(1)
return len(self.sourceitems) > 0
def waitUncommentableSourceIfNecessary(self):
"""souce cannot comment within 10 minutes after download"""
url = 'http://download.csdn.net/my/downloads/1'
maxMinutes = 11
for i in range(0, maxMinutes):
html = self.getUrlContent(self.sess, url)
if html is None:
break
soup = BeautifulSoup(html)
sourcelist = soup.findAll('span', attrs={'class' : 'btn-comment'})
if sourcelist is None or len(sourcelist) == 0:
print('None uncommentable source now!')
break
print('Waiting for uncommentable source count down %d minutes.' % (maxMinutes-i))
time.sleep(60)
def getPageCount(self):
"""get downloaded resources page count"""
url = 'http://download.csdn.net/my/downloads'
html = self.getUrlContent(self.sess, url)
if html is None:
print('Get pagecount failed')
return 0
soup = BeautifulSoup(html)
pagelist = soup.findAll('a', attrs={'class' : 'pageliststy'})
if pagelist is None or len(pagelist) == 0:
return 0
lasthref = pagelist[len(pagelist) - 1].get('href', None)
if lasthref is None:
return 0
return int(filter(str.isdigit, str(lasthref)))
def comment(self, sourceid):
"""comment per source"""
print('sourceid %s commenting...' % sourceid)
contents = [
'It just soso, but thank you all the same.',
'Neither good nor bad.',
'It is a nice resource, thanks for share.',
'It is useful for me, thanks.',
'I have looking this for long, thanks.'
]
rating = self.getSourceRating(sourceid)
print('current rating is %d.' % rating)
if rating == 0: # nobody comments
rating = 3
content = contents[rating - 1]
t = '%d' % (time.time() * 1000)
paramsmap = {
'sourceid' : sourceid,
'content' : content,
'rating' : rating,
't' : t
}
params = urllib.urlencode(paramsmap)
url = 'http://download.csdn.net/index.php/comment/post_comment?%s' % params
html = self.getUrlContent(self.sess, url)
if html is None or html.find('({"succ":1})') == -1:
print('sourceid %s comment failed! response is %s.' % (sourceid, html))
else:
print('sourceid %s comment succeed!' % sourceid)
def getSourceRating(self, sourceid):
"""get current source rating"""
rating = 3
url = 'http://download.csdn.net/detail/%s/%s' % (self.sourceitems[sourceid], sourceid)
html = self.getUrlContent(self.sess, url)
if html is None:
return rating
soup = BeautifulSoup(html)
ratingspan = soup.findAll('span', attrs={'class': 'star-yellow'})
if ratingspan is None or len(ratingspan) == 0:
return rating
ratingstyle = ratingspan[0].get('style', None)
if ratingstyle is None:
return rating
rating = int(filter(str.isdigit, str(ratingstyle))) / 15
return rating
@staticmethod
def getElementValue(soup, element_name, element_value):
element = soup.find(attrs={element_name : element_value})
if element is None:
return None
return element.get('value', None)
@staticmethod
def isLoginSuccess(response):
if response is None or response.status_code != 200:
return False
return -1 != response.content.find('lastLoginIP')
@staticmethod
def getUrlContent(session, url):
html = None
try:
response = session.get(url)
if response is not None:
html = response.text
except requests.exceptions.ConnectionError as e:
# traceback.print_exc()
pass
return html
def main():
csdn = CsdnCommenter()
while csdn.login() is False:
print('Login failed! Please try again.')
print('Login succeed!')
csdn.autoComment()
if __name__ == '__main__':
main()
Informações:
- Autor:Alex Yucra
- Link:https://alexyucra.github.io/blog/2014/10/12/csdnresautocomment/
- Declaração de direitos autorais: atribuição gratuita de reimpressão-não-comercial-não-derivada-manter(Licença Creative Commons 3.0)